本文目录
文本摘要
所谓摘要,就是对给定的单个或者多个文档进行梗概,即在保证能够反映原文档的重要内容的情况下,尽可能地保持简明扼要。质量良好的文摘能够在信息检索过程中发挥重要的作用,比如利用文摘代替原文档参与索引,可以有效缩短检索的时间,同时也能减少检索结果中的冗余信息,提高用户体验。随着信息爆炸时代的到来,自动文摘逐渐成为自然语言处理领域的一项重要的研究课题。
分类
按照摘要面向的文档类型,可以将其分为单文档摘要和多文档摘要。根据需要产生摘要的文档长度,可以将摘要分为长文摘要、短文摘要。按照摘要的生成方法,可以将它分为抽取式摘要和生成式摘要。抽取式摘要是通过抽取拼接源文档中的关键句子来生成摘要的,生成式摘要则是系统根据文档表达的重要内容,自行组织语言,对源文档进行概括。后者是比较常见的划分方式,因为抽取式摘要和生成式摘要在生成过程中有较大的区别。本文后续对摘要生成方法的分类,也是根据这种方式进行划分。
评价指标
摘要的评估可以参照下图:
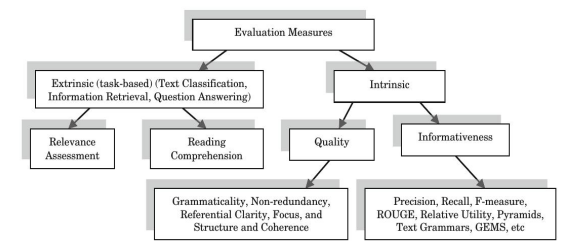
其中:
-
Extrinsic,外在评价,在一些大的任务中,如信息检索,问答,文本分类等等,摘要只是其中的一个模块,
外在评价就是从摘要所服务的下游任务的效果(如检索中的召回率,文本分类中的F1分数值)对摘要进行评价。
-
Intrinsic,内部评价,即从摘要本身进行评估,主要包括两个方面:
-
摘要质量,如摘要的冗余性、可读性、流畅程度等等,一般是由专家进行打分,成本较高;
-
摘要的信息性,一般是通过与标准摘要进行比对,通过计算得出,学术界常用的指标有ROUGE-N、ROUGE-L、BLUE、METEOR等等。
-
数据集
抽取式摘要
抽取式方法从原文中选取关键句组成摘要。这种方法天然的在语法、句法上错误率低,保证了一定的效果。传统的抽取式摘要方法使用图方法、聚类等方式完成无监督摘要。当下流行的有监督摘要的方法,一种是先提取词语、句子级别的各类特征,比如句子的长度、位置、句子中的词语的TF-IDF值等等,然后利用机器学习的算法对句子进行抽取。或者是基于神经网络的抽取式摘要往往将问题建模为序列标注和句子排序两类任务。下面我们将简单介绍这些算法:
传统方法
Lead-3
一般来说,作者常常会在标题和文章开始就表明主题,因此最简单的方法就是抽取文章中的前几句作为摘要。Lead-3即抽取文章的前三句作为文章的摘要。Lead-3 方法虽然简单直接,但却是非常有效的方法。
TextRank
TextRank 算法仿照 PageRank,将句子作为节点,使用句子间相似度,构造无向有权边。使用边上的权值迭代更新节点值,最后选取 N 个得分最高的节点,作为摘要。
聚类
将文章中的句子视为一个点,按照聚类的方式完成摘要。首先将句子转化为向量表示(这一过程不同的论文做法可能不同),再使用 K 均值聚类和 Mean-Shift 聚类进行句子聚类,得到 K个类别。最后从每个类别中,选择距离质心最近的句子,得到 K 个句子,作为最终摘要。
基于深度学习的方法
抽取式摘要可以建模为序列标注任务进行处理,其核心想法是:为原文中的每一个句子打一个二分类标签(0 或 1),0 代表该句不属于摘要,1 代表该句属于摘要。最终摘要由所有标签为 1 的句子构成。将抽取式摘要建模成序列标注问题后,就可以应用序列标注中的方法来进行句子标注了。比如BiLSTM、BiLSTM+CRF等等。
该模型的一个问题是,模型的训练需要监督数据,现有数据集往往没有对应的句子级别的标签,因此需要通过启发式规则进行获取。具体方法为:首先选取原文中与标准摘要计算 ROUGE 得分最高的一句话加入候选集合,接着继续从原文中进行选择,保证选出的摘要集合 ROUGE 得分增加,直至无法满足该条件。得到的候选摘要集合对应的句子设为 1 标签,其余为 0 标签。
除此之外,当下最新的论文还有基于深度学习还有强化学习对句子进行打分的方法:
1.SWAP-NET : Extractive Summarization with SWAP-NET: Sentences and Words from Alternating Pointer Networks
2.NN-SE : [Neural summarization by extracting sentences and words
3.BANDITSUM :BANDITSUM: Extractive Summarization as a Contextual Bandit
4.SummaRuNNer: A recurrent neural network based sequence model for extractive summarization of documents
5.Refrech: Ranking sentences for extractive summarization with reinforcement learning
6.DQN: Deep reinforcement learning for extractive document summarization:
7.RNES w/o coherence :Learning to Extract Coherent Summary via Deep Reinforcement Learning
生成式摘要
抽取式摘要在语法、句法上有一定的保证,但是也面临了一定的问题,例如:内容选择错误、连贯性差、灵活性差等问题。生成式摘要允许摘要中包含新的词语或短语,灵活性高,随着近几年神经网络模型的发展,序列到序列(Seq2Seq)模型被广泛的用于生成式摘要任务,并取得不错的效果。
但是简单的Seq2seq直接应用到摘要生成会有一些问题,比如重复生成、信息冗余,无法处理未登录词,关键信息丢失,可读性差等等。相对应的改进主要有以下几类:
- copy机制,在每一次解码的时候,计算一个概率,根据这个概率选择是否从原文中复制词语,有效解决未登录词的问题;
- coverage机制,让注意力机制避免多次在同一个地方赋予高权重,避免重复;
- 针对长文档使用更复杂的encoder-decoder,实现更好地对信息编码,解码;
- 对注意力机制进行改进,融合文章的关键信息;
- 结合抽取式的方法,比如先抽取多个重要的句子,然后结合这些句子进行改写;
- 针对序列生成过程中的Exposure Bias还有训练损失和评价指标不一致的问题,加入强化学习的机制,用强化学习来训练网络;
- 受Bert启发,使用预训练语言模型,专门针对序列到序列的自然语言生成任务,比如2019年ICML上微软提出的MASS:
总结
毫无疑问,文本摘要最核心的问题是确定关键信息,在生成摘要的时候,要将这些关键信息融入进去,同时要尽量避免出现重复、可读性差、这些问题。 关于文本摘要未来的方向,可以考虑从以下几个方面入手:
- 能不能使用更少的数据进行学习,或者是研究一下无监督型的摘要;
- 现在的数据集大多集中在新闻领域,在这上面训练好的模型应用到其他领域的话效果并不好,即模型的适应性不够好;
- 能不能尝试设计新的评价指标,更好地自动评估摘要的质量;