本文目录
生成对抗网络
主要思想
生成式对抗网络(Generative Adversarial Networks,简称GANs)的主要框架如下图所示:
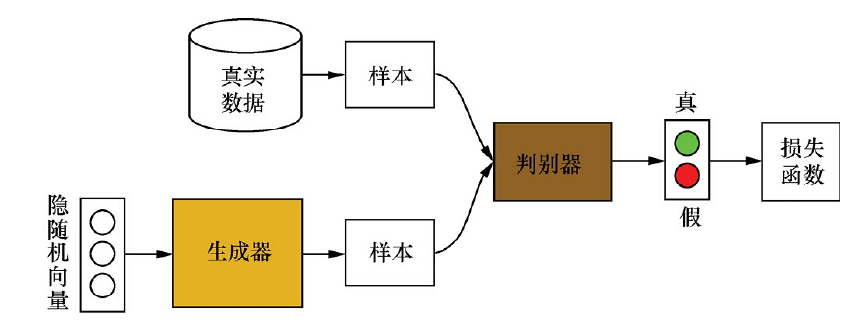
GANs主要包括生成器(Generator)和判别器(Discriminator)两个部分。其中,生成器用于合成“假”样本,判别器用于判断输入的样本是真实的还是合成的。具体来说,生成器从先验分布中采得随机信号,经过神经网络的变换,得到模拟样本;判别器既接收来自生成器的模拟样本,也接收来自实际数据集的真实样本,但我们并不告诉判别器样本来源,需要它自己判断。
GANs采用对抗策略进行模型训练,一方面,生成器通过调节自身参数,使得其生成的样本尽量难以被判别器识别出是真实样本还是模拟样本;另一方面,判别器通过调节自身参数,使得其能尽可能准确地判别出输入样本的来源。具体训练时,采用生成器和判别器交替优化的方式:
- 在训练判别器时,先固定生成器,然后利用生成器随机模拟产生负样本,并从真实数据集中采样获得正样本,将这些正负样本输入到判别器中,根据判别器的输出和样本标签来计算误差;最后利用误差反向传播算法来更新判别器D的参数。
- 在训练生成器时,先固定判别器D,然后利用当前生成器G随机模拟产生样本,并输入到判别器D中,根据判别器的输出和样本标签计算误差,最后利用误差反向传播算法来更新生成器G的参数。
GAN有着十分多的变种,比较出名的有WGAN,DCGAN,SEQGAN等等。
优点与不足
GAN 的优点: (以下部分摘自ian goodfellow 在Quora的问答)
● GAN是一种生成式模型,相比较其他生成模型(玻尔兹曼机和GSNs)只用到了反向传播,而不需要复杂的马尔科夫链
● 相比其他所有模型, GAN可以产生更加清晰,真实的样本
● GAN采用的是一种无监督的学习方式训练,可以被广泛用在无监督学习和半监督学习领域
● 相比于变分自编码器, GANs没有引入任何决定性偏置( deterministic bias),变分方法引入决定性偏置,因为他们优化对数似然的下界,而不是似然度本身,这看起来导致了VAEs生成的实例比GANs更模糊
● 相比VAE, GANs没有变分下界,如果鉴别器训练良好,那么生成器可以完美的学习到训练样本的分布.换句话说,GANs是渐进一致的,但是VAE是有偏差的
● GAN应用到一些场景上,比如图片风格迁移,超分辨率,图像补全,去噪,避免了损失函数设计的困难,不管三七二十一,只要有一个的基准,直接上判别器,剩下的就交给对抗训练了。
GAN的缺点:
● 训练GAN需要达到纳什均衡,有时候可以用梯度下降法做到,有时候做不到.我们还没有找到很好的达到纳什均衡的方法,所以训练GAN相比VAE或者PixelRNN是不稳定的,但我认为在实践中它还是比训练玻尔兹曼机稳定的多
● GAN不适合处理离散形式的数据,比如文本
● GAN存在训练不稳定、梯度消失、模式崩溃的问题(目前已解决)
训练GAN的一些技巧
1. 输入规范化到(-1,1)之间,最后一层的激活函数使用tanh(BEGAN除外)
2. 使用wassertein GAN的损失函数,
3. 如果有标签数据的话,尽量使用标签,也有人提出使用反转标签效果很好,另外使用标签平滑,单边标签平滑或者双边标签平滑
4. 使用mini-batch norm, 如果不用batch norm 可以使用instance norm 或者weight norm
5. 避免使用RELU和pooling层,减少稀疏梯度的可能性,可以使用leakrelu激活函数
6. 优化器尽量选择ADAM,学习率不要设置太大,初始1e-4可以参考,另外可以随着训练进行不断缩小学习率,
7. 给判别器的网络层增加高斯噪声,相当于是一种正则