本文目录
强化学习
强化学习(Reinforcement Learning)是一种重要的机器学习方法,它的主要思想是与环境交互和试错,利用环境的评价性反馈信号实现决策的优化。这也是自然界中人类或动物学习的基本途径。
强化学习系统与环境的关系如图所示:
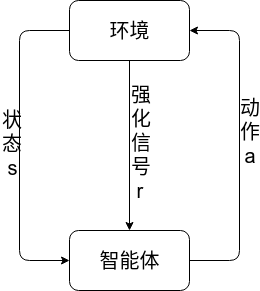
在每一时刻,智能体与环境的交互过程如下:
- 智能体感知环境的状态$s_{t} \in S$,其中$S$为状态空间;
- 智能体基于感知的状态,根据某种策略选择一个动作 $a_{t} \in A_{s_{t}}$,其中$A_{s_{t}}$为状态$s_{t}$下可选择的动作空间;
- 在第二步选择的动作的作用下,环境转移到一个新的状态 $s_{t+1} \in S$ 并产生一个强化信号$r(s_{t},a_{t}) \in R$ ;
- 强化信号返回给智能体,智能体根据这个信号调整动作模块。
强化学习把学习看成是一个试探性的过程。智能体选择一个动作作用于环境,随后环境的状态发生变化,同时产生一个强化信号(奖或惩)反馈给智能体,智能体根据强化信号和环境当前状态再选择下一个动作,选择的原则是使受到正强化值(奖)的概率增大。选择的动作不仅影响目前状态的强化值,还影响下一时刻的状态以及最终的强化值。
强化学习系统具有以下的特点:
- 适应性(Adaptive), 即智能体不断利用环境中的反馈信息来改善其性能,也就是说,智能体能够很好的适应环境的变化。
- 反应性(Reactive),即智能体可以从经验中直接获取状态动作规则。
- 只需要根据强化信号即可进行学习,这使得在面临十分复杂的无法精确的进行数学建模的环境时,强化学习可以大有用处。
如何根据环境的反馈来不断逼近最优策略,是强化学习研究的重要问题。按照策略评估、控制方式的不同,强化学习的算法主要有:蒙特卡罗算法、时序差分算法、Q 学习算法、Sarsa 学习算法等等。随着强化学习在算法和理论方面研究的深入,强化学习算法在实际的工程优化和控制中得到了广泛的应用。目前强化学习方法已经在非线性控制、机器人控制、人工智能问题求解、组合优化和调度、通信和数字信号处理、多智能体、模式识别和交通信号控制等领域取得了若干成功的应用。
分类
强化学习的分类如下:
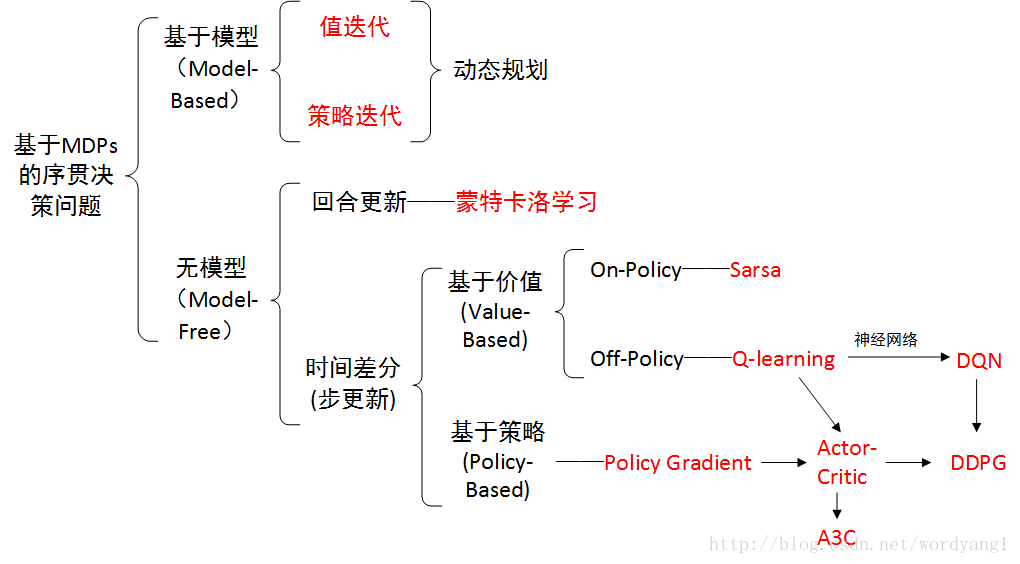
划分的要点如下:
有模型学习以及免模型学习的区别:
如果强化学习任务对应的马尔可夫决策过程四元组 $E = (X, A, P, R)$ 已知,其中$X$为状态空间,$A$为动作空间,$P$为状态转移概率分布,$R$是奖赏分布。那么这种情形称为“模型已知”,在已知模型的环境中进行学习称为“有模型学习”,在模型未知的情况下进行学习称为“免模型学习”。
值迭代以及策略迭代的区别:
本质上,Policy Iteration和Value Iteration都属于Model-based方法。
策略迭代:
从一个初始策略(通常是随机策略)出发,先进行策略评估,然后改进策略,评估改进的策略,再进一步改进策略,…..不断迭代进行策略评估和改进,直到策略收敛,不再改变为止。这种做法称为策略迭代。
1.策略迭代的第二步policy evaluation与值迭代的第二步finding optimal value function十分相似,除了后者用了max操作,前者没有max.因此后者可以得出optimal value function, 而前者不能得到optimal function. 值迭代可以看成是 策略迭代的一种简化。
2.策略迭代的收敛速度更快一些,在状态空间较小时,最好选用策略迭代方法。当状态空间较大时,值迭代的计算量更小一些
回合更新以及时间差分(步更新)的区别: 回合更新的蒙特卡罗强化学习算法在完成一个采样轨迹之后再更新策略的值估计, 基于时序差分的算法则能够 在每执行一步策略后就进行值函数更新。
on-policy and off-policy(同策略 与 异策略) 同策略:被评估与被改进的是同一个策略
基于值与基于策略的区别: 基于值的方法中:通过学习得到值函数的近似,通过这个值函数评估策略的好坏,选择采取哪种策略 在policy-based方法中,实际上并没有学习到一个值函数,来帮助我们了解某一状态下各动作的奖励是多少。而是直接学习策略函数,将状态映射为动作。
深度强化学习
深度强化学习(deep reinforcement learning)是将强化学习和深度学习结合在一起,用强化学习来定义问题和优化目标,用深度学习来解决策略和值函数的建模问题,然后使用误差反向传播算法来优化目标函数。深度强化学习在一定程度上具备解决复杂问题的通用智能,并在很多任务上都取得了很大的成功。