本文目录
概率图模型
概率图模型 (Probabilistic Graphical Model, PGM), 简称图模型 (Graphical Model,GM),是指一种用图结构来描述多元随机变量之间条件独立关系的概 率模型,从而给研究高维空间中的概率模型带来了很大的便捷性。
在概率图模型中,数据(样本)由公式 $G=(V,E)$ 建模表示:
- $V$ 表示节点,即随机变量(放在此处的,可以是一个token或者一个label),具体地,用 $Y = (y_{1}, {\cdots}, y_{n} ) $ 为随机变量建模,注意 $Y $ 现在是代表了一批随机变量(想象对应一条sequence,包含了很多的token), $ P(Y) $ 为这些随机变量的分布;
- $E$ 表示边,即概率依赖关系。具体咋理解,还是要在后面结合HMM或CRF的graph具体解释。
概率图模型的体系如下所示:
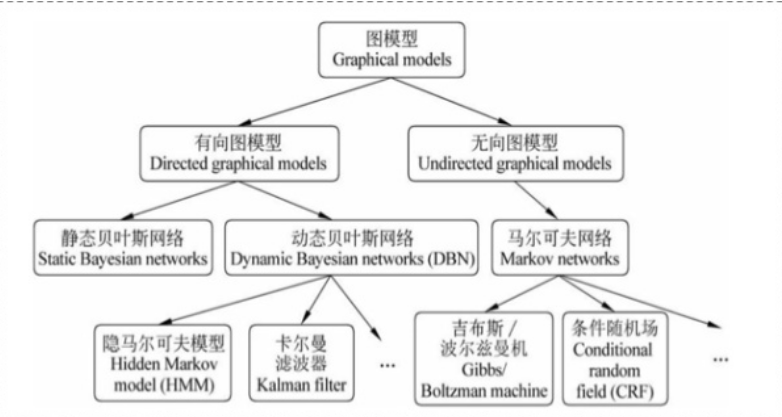
基本概念
有向图模型和无向图模型差异:
- 有向图模型(如贝叶斯网络)适合为有单向依赖的数据建模
- 无向图模型(如马尔可夫网络)适合实体之间相互依赖的建模
具体地,它们的核心差异表现在如何求$P = (X)$,即怎么表示$ X= (x_1, \cdots, x_n)$这个的联合概率。
对于有向图模型,联合概率的计算方式为:$P(x_{1}, {\cdots}, x_{n} )=\prod_{i=0}P(x_{i} | \pi(x_{i}))$,其中$\pi(x_i)$表示指向节点$x_i$的节点集合。
对于无向图模型,联合概率的计算方式为:$P(Y )=\frac{1}{Z(x)} \prod_{c}\psi_{c}(Y_{c} ) $, 其中 $Z(x) = \sum_{Y} \prod_{c}\psi_{c}(Y_{c} )$ ,归一化是为了让结果算作概率,而 $ \psi_{c}(Y_{c} )$ 是一个最大团 $C$ (即最大连通子图)上随机变量们的联合概率,一般取指数函数:
\[\psi_{c}(Y_{c} ) = e^{-E(Y_{c})} =e^{\sum_{k}\lambda_{k}f_{k}(c,y|c,x)}\]这个东西叫做势函数。那么概率无向图的联合概率分布可以在因子分解下表示为:
齐次马尔可夫性假设:
马尔科夫链 $(x_{1},\cdots,x_{n})$ 里的 $ x_{i}$ 总是只受 $ x_{i-1}$的影响。
马尔可夫过程:
在一个过程中,每个状态的转移只依赖于前n个状态,并且只是个n阶的模型。最简单的马尔科夫过程是一阶的,即只依赖于前一个状态。
隐马尔可夫模型(Hidden Markov Model,HMM)
三个要素
隐马尔可夫模型描述由一个隐藏的马尔科夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测而产生观测随机序列的过程。隐马尔可夫模型由初始状态分布,状态转移概率矩阵以及观测概率矩阵三个要素所确定:
- $A$ ,状态转移概率矩阵, \(A= [a_{ij}]_{N \times N}\) (N为隐藏状态集元素个数),其中 \(a_{ij} = P(i_{t+1} = q_j |i_{t} = q_i)\),表示在时刻t处于状态$q_i$条件下在时刻$t+1$转移到状态$q_j$的概率。
- $B$ ,观测概率矩阵,\(B=\left[b_{j}(k)\right]_{N \times M}\)(N为隐藏状态集元素个数,M为观测集元素个数),其中 \(b_{j}(k)=P\left(o_{t}=v_{k} | i_{t}=q_{j}\right), \quad k=1,2, \cdots, M ; j=1,2, \cdots, N\) 是在时刻t处于状态$q_j$的条件下生成观测$v_k$的概率。
- $π$ ,初始状态分布,$\pi = (\pi_i)$其中$\pi_i = P(i_1 = q_i), i = 1,2, \cdots, N$是时刻$t=1$处于状态$q_i$的概率。
所以隐马尔可夫模型$\lambda$可以用三元符号表示,即:
\[\lambda = (A, B, \pi)\]两个基本假设
隐马尔可夫模型做了两个基本假设:
- 齐次马尔可夫性假设,即假设隐藏的马尔可夫链在任意时刻$t$的状态只依赖于其前一时刻的状态,与其他时刻的状态及观测无关,也与时刻$t$无关。
- 观测独立性假设,即假设任意时刻的观测只依赖于该时刻的马尔可夫链的状态,与其他观测及状态无关。
应用于标注问题
隐马尔可夫模型可以用于标注,这时状态对应着标记(无法观测)。标注问题是给定观测的序列预测其对应的标记序列。可以假设标注问题的数据是由隐马尔可夫模型生成的。这样我们可以利用隐马尔可夫模型的学习与预测算法进行标注。
比如在使用HMM解决NER这种序列标注问题的时候,我们所能观测到的是字组成的序列(观测序列),观测不到的是每个字对应的标注(状态序列)。
对应的,HMM的三个要素可以解释为,初始状态分布就是每一个标注作为句子第一个字的标注的概率,状态转移概率矩阵就是由某一个标注转移到下一个标注的概率(设状态转移矩阵为$M$,那么若前一个词的标注为$tag_i$ ,则下一个词的标注为$tag_j$的概率为 $M_{ij}$),观测概率矩阵就是指在某个标注下,生成某个词的概率。
三个基本问题
隐马尔可夫模型有3个基本问题:
- 概率计算问题,给定模型$\lambda = (A, B, \pi)$和观测序列$O = (o_1, o_2, …, o_T)$,计算在模型$\lambda$下观测序列$O$出现的概率$P(O | \lambda)$
- 学习问题。已知观测序列$O=(o_1,o_2,…,o_T)$,估计模型$\lambda = (A, B, \pi)$参数,使得在该模型下观测序列概率$P(O| \lambda)$最大,即用极大似然估计的方法估计模型参数
- 预测问题,已知模型$\lambda = (A, B, \pi)$和观测序列$O = (o_1, o_2, …, o_T)$,求对给定观测序列条件概率$P(I | O)$最大的状态序列$I$。即给定观测序列和模型参数,求最有可能的对应的状态序列。
概率计算算法
有三种方法解决概率计算问题:
-
直接计算法,按概率公式直接计算$P(O | \lambda)=\sum_{I} P(O | I, \lambda) P(I | \lambda)$, 这样做的话计算量太大,不可行。复杂度$O(TN^T)$。
-
前向算法:

其中$\alpha_t(j)$是到时刻$t$观测到$o_1, o_2, …, o_t$并在时刻$t$处于状态$q_j$的前向概率,那么乘积$\alpha_t(j)a_{ji}$就是到时刻$t$观测到$o_1, o_2, …, o_t$并在时刻$t$处于状态$q_j$而在时刻$t+1$到达状态$q_i$的联合概率。所以$\left[\sum_{j=1}^{N} \alpha_{t}(j) a_{j i}\right]$就表示结果就是到时刻$t$观测为$o_1,o_2,…,o_t$并在时刻$t+1$处于状态$q_i$的联合概率。下面这张图帮助理解前向概率的递推公式:
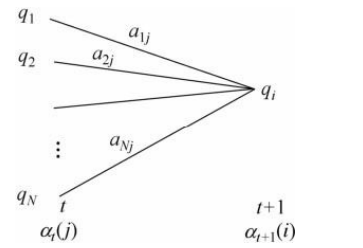
前向算法减少计算量的原因在于每一次计算直接引用前一个时刻的计算结果,避免重复计算。它的复杂度是$O(N^2T)$。
-
后向算法,与前向算法类似:
输入:隐马尔可夫模型$\lambda$,观测序列$O$; 输出:观测序列概率$P(O| \lambda )$。
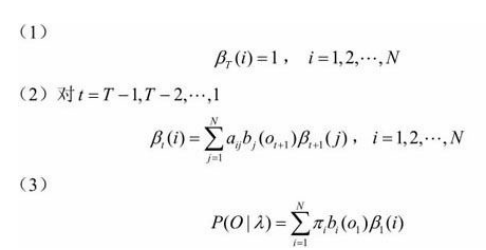
后向概率$\beta_t(i)$的定义:在时刻$t$状态为$q_i$条件下时刻$t+1$之后的观测序列为$o_{t+1},o_{t+2},…,o_{T}$的概率。第一步初始化,第二步递推,第三步就可以求结果了。其中递推公式:
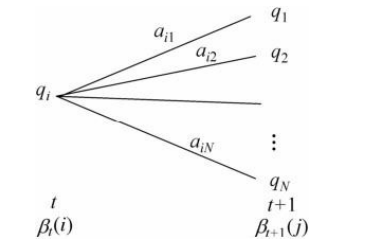
算法的复杂度也是$O(N^2T)$
学习算法
根据训练数据是包括观测序列以及对应的状态序列还是只有观测序列可以分别由监督学习与非监督学习两种实现。
监督学习方法
使用极大似然的方法来估计隐马尔可夫模型的参数即可。
- 设样本中时刻$t$处于状态$i$时刻$t+1$转移到状态j的频数为$A_{ij}$,那么转移概率$a_{ij}$的估计:
- 设样本中状态为j并观测为k的频数是$B_{jk}$,那么状态为j观测为k的概率$b_j(k)$的估计是:
-
初始状态概率 $\pi_i$的估计$\hat{\pi_i}$为S个样本中初始状态为$q_i$的频率
Baum-Welch算法(EM算法)
假设给定训练数据只包含S个长度为T的观测序列${O_1,O_2,…,O_S}$而没有对应的状态序列,目标是学习隐马尔可夫模型 $\lambda =(A,B, \pi )$的参数。我们将观测序列数据看作观测数据$O$,状态序列数据看作不可观测的隐数据$I$ ,那么隐马尔可夫模型事实上是一个含有隐变量的概率模型:
\[P(O | \lambda)=\sum_{I} P(O | I, \lambda) P(I | \lambda)\]它的参数学习可以由EM算法实现:

预测算法
近似算法
近似算法的想法是,在每个时刻t选择在该时刻最有可能出现的状态。
在时刻t处于状态$q_i$的概率$\gamma_t(i)$是:
\[\gamma_{t}(i)=\frac{\alpha_{t}(i) \beta_{t}(i)}{P(O | \lambda)}=\frac{\alpha_{t}(i) \beta_{t}(i)}{\sum_{j=1}^{N} \alpha_{t}(j) \beta_{t}(j)}\]在每一时刻选择其中最大的一个即可。
这样做的优点是计算简单,缺点是不能保证预测的状态序列整体是最有可能的状态序列,因为这样得到的状态序列中有可能存在转移概率为0的相邻状态。
维特比算法
维特比算法实际是用动态规划解隐马尔可夫模型预测问题,即用动态规划求概率最大路径(最优路径)。这时一条路径对应着一个状态序列。
简单叙述:我们从时刻$t=1$开始,递推地计算在时刻$t$状态为$i$的各条部分路径的最大概率,直至得到时刻$t$=$T$状态为$i$的各条路径的最大概率。时刻$t$=$T$的最大概率即为最优路径的概率$P^*$,最优路径的终结点 也同时得到。之后,为了找出最优路径的各个结点,从终结点开始,由后向前逐步求得结点,(利用回溯法)得到最优路径。这就是维特比算法。
完整的叙述:先定义两个变量
- 在时刻t状态为i的所有单个路径$(i_1, i_2, …. , i_t)$中的概率最大值为 $\delta_t(i)$,递推公式:
- 定义在时刻t状态为i的所有单个路径$(i_1, i_2, …. , i_t)$中概率最大的路径的第$t-1$个结点为:
维比特算法的流程如下:

最大熵马尔可夫模型
HMM中,观测节点 $o_{i}$ 依赖隐藏状态节点 $i_{i}$ ,也就意味着我的观测节点只依赖当前时刻的隐藏状态。但在更多的实际场景下,观测序列是需要很多的特征来刻画的,比如说,我在做NER时,我的标注 $i_{i}$ 不仅跟当前状态 $o_{i}$ 相关,而且还跟前后标注 $o_{j}(j \neq i)$ 相关,比如字母大小写、词性等等。
为此,提出来的MEMM模型就是能够直接允许“定义特征”,直接学习条件概率,即
\[P(i_{i}|i_{i-1},o_{i}) (i = 1,\cdots,n)\]总体为:
\[P(I|O) = \prod_{t=1}^{n}P(i_{i}|i_{i-1},o_{i}), i = 1,\cdots,n\]并且, $P(i|i^{‘},o)$ 这个概率通过最大熵分类器建模(取名MEMM的原因):
\[P(i|i^{'},o) = \frac{1}{Z(o,i^{'})} exp(\sum_{a})\lambda_{a}f_{a}(o,i)\]重点来了,这是ME的内容,也是理解MEMM的关键: $Z(o,i^{‘})$ 这部分是归一化; $f_{a}(o,i)$ 是特征函数,具体点,这个函数是需要去定义的; $λ$ 是特征函数的权重,这是个未知参数,需要从训练阶段学习而得。
比如我可以这么定义特征函数:
\[\begin{equation} f_{a}(o,i) = \begin{cases} 1& \text{满足特定条件},\\ 0& \text{other} \end{cases} \end{equation}\]其中,特征函数 $ f_{a}(o,i)$ 个数可任意制定, $(a = 1, \cdots, n)$
所以总体上,MEMM的建模公式这样:
\[P(I|O) = \prod_{t=1}^{n}\frac{ exp(\sum_{a})\lambda_{a}f_{a}(o,i) }{Z(o,i_{i-1})} , i = 1,\cdots,n\]是的,公式这部分之所以长成这样,是由ME模型决定的。
注意,MEMM是判别式模型,直接对条件概率建模。 上图:
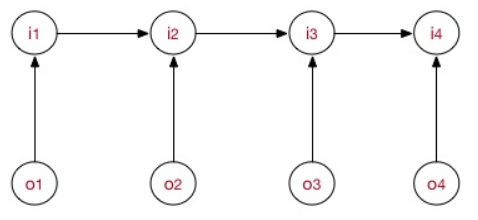
作为对比,HMM模型可用下图表示:
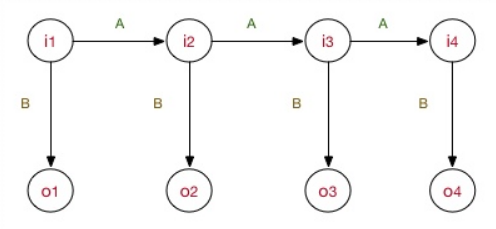
MEMM模型的工作流程也包括了学习训练问题、预测问题、序列求概率问题。
对于学习问题,MEMM模型需要学习里面的特征权重$\lambda$。但是跟HMM不同的是,因为HMM是生成式模型,参数即为各种概率分布元参数,数据量足够可以用最大似然估计。而判别式模型是用函数直接判别,学习边界,MEMM即通过特征函数来界定。但同样,MEMM也有极大似然估计方法、梯度下降、牛顿迭代发、拟牛顿下降、BFGS、L-BFGS等等。各位应该对各种优化方法有所了解的。
对于预测问题,使用维特比算法即可。
存在的缺陷:标注偏置问题,即MEMM倾向于选择拥有更少转移的状态。这是因为局部归一化的原因,隐状态会倾向于转移到那些后续状态可能更少的状态上,以提高整体的后验概率。从而导致标注偏置问题。而CRF在最大熵马尔可夫模型的基础上,进行了全局归一化,可以有效解决这个问题。
CRF
条件随机场( conditional random field, CRF)是给定一组输入随机变量下另一组输出随机变量的条件概率分布模型,其特点是假设输出随机变量构成马尔可夫随机场,条件随机场可以用于不同的预测问题,因为线性链条件随机场在序列标注问题上面的应用比较多,所以下面讨论的条件随机场,指的就是线性链条件随机场。
线性链条件随机场的示意图如下:
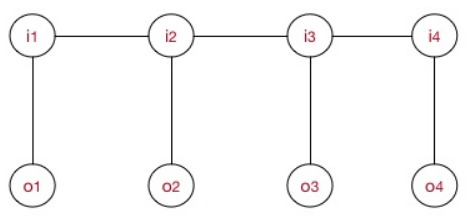
其中,每一个( $I_{i} \sim O_{i}$ )对为一个最大团,即在上式中 $c = i$ 。并且线性链CRF满足
\[P(I_{i}|O,I_{1},\cdots, I_{n}) = P(I_{i}|O,I_{i-1},I_{i+1})\]所以CRF的建模公式如下:
\[P(I | O)=\frac{1}{Z(O)} \prod_{i}\psi_{i}(I_{i}|O ) = \frac{1}{Z(O)} \prod_{i} e^{\sum_{k}\lambda_{k}f_{k}(O,I_{i-1},I_{i},i)} = \frac{1}{Z(O)} e^{\sum_{i}\sum_{k}\lambda_{k}f_{k}(O,I_{i-1},I_{i},i)}\]在这个建模公式中:
- 下标i表示我当前所在的节点(token)位置。
- 下标k表示我这是第几个特征函数,并且每个特征函数都附属一个权重 $\lambda_{k}$ ,也就是这么回事,每个团里面,我将为 $token_{i}$ 构造M个特征,每个特征执行一定的限定作用,然后建模时我再为每个特征函数加权求和。
- $Z(O)$ 是用来归一化的,这是为了将其转化为概率值。
- $P(I|O)$ 这个表示什么?具体地,表示了在给定的一条观测序列 $O=(o_{1},\cdots, o_{i})$ 条件下,我用CRF所求出来的隐状态序列 $I=(i_{1},\cdots, i_{i})$ 的概率,注意,这里的I是一条序列,有多个元素(一组随机变量),而至于观测序列 $O=(o_{1},\cdots, o_{i})$ ,它可以是一整个训练语料的所有的观测序列;也可以是在inference阶段的一句sample,比如说对于序列标注问题,我对一条sample进行预测,可能能得到 $P_{j}(I | O)(j=1,…,J)$J条隐状态I,但我肯定最终选的是最优概率的那条(by viterbi)。这一点希望你能理解。
对于CRF,可以为他定义两款特征函数:转移特征&状态特征。 我们将建模总公式展开:
\[\begin{align} P(I | O) &=\frac{1}{Z(O)} e^{\sum_{i}^{T}\sum_{k}^{M}\lambda_{k}f_{k}(O,I_{i-1},I_{i},i)} \\ &=\frac{1}{Z(O)} e^{ [ \sum_{i}^{T}\sum_{j}^{J}\lambda_{j}t_{j}(O,I_{i-1},I_{i},i) + \sum_{i}^{T}\sum_{l}^{L}\mu_{l}s_{l}(O,I_{i},i) ] } \end{align}\]其中:
- $t_{j}(O,I_{i-1},I_{i},i)$ 为$i$处的转移特征,对应权重 $\lambda_{j}$ ,每个 $token_{i}$ 都有$J$个特征,转移特征针对的是前后token之间的限定。举个例子:
- $s_{l}(O,I_{i},i)$为处$i$的状态特征,对应权重$\mu_l$,每个$token_i$都有$L$个特征,举个例子:
不过一般情况下,我们不把两种特征区别的那么开,合在一起:
\[P(I | O)=\frac{1}{Z(O)} e^{\sum_{i}^{T}\sum_{k}^{M}\lambda_{k}f_{k}(O,I_{i-1},I_{i},i)}\]满足特征条件就取值为1,否则没贡献。
还可以把特征函数部分抠出来:
\[Score = \sum_{i}^{T}\sum_{k}^{M}\lambda_{k}f_{k}(O,I_{i-1},I_{i},i)\]是的,我们为 $token_{i}$ 打分,满足条件的就有所贡献。最后将所得的分数进行log线性表示,求和后归一化,即可得到概率值……所以条件随机场可以看成是一种log线性模型:
log-linear models take the following form: $P(y|x;\omega) = \frac{ exp(\omega·\phi(x,y)) }{ \sum_{y^{‘}\in Y }exp(\omega·\phi(x,y^{‘})) }$
CRF的学习训练过程:
一套CRF由一套参数λ唯一确定(先定义好各种特征函数)。
同样,CRF用极大似然估计方法、梯度下降、牛顿迭代、拟牛顿下降、IIS、BFGS、L-BFGS等等。各位应该对各种优化方法有所了解的。其实能用在log-linear models上的求参方法都可以用过来。
序列标注(预测)过程:
使用维特比算法。
总结
NB在sequence建模下拓展到了HMM;LR在sequence建模下拓展到了CRF。
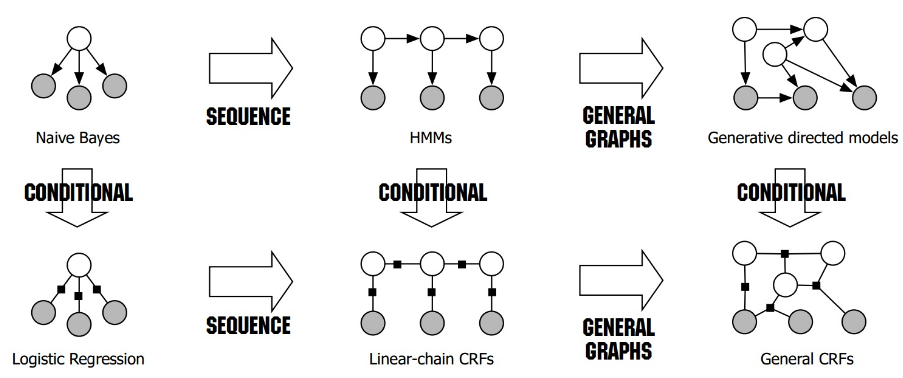
三者的比较:
- HMM -> MEMM: HMM模型中存在两个假设:一是输出观察值之间严格独立,二是状态的转移过程中当前状态只与前一状态有关。但实际上序列标注问题不仅和单个词相关,而且和观察序列的长度,单词的上下文,等等相关。MEMM解决了HMM输出独立性假设的问题。因为HMM只限定在了观测与状态之间的依赖,而MEMM引入自定义特征函数,不仅可以表达观测之间的依赖,还可表示当前观测与前后多个状态之间的复杂依赖。
- MEMM -> CRF:
- CRF不仅解决了HMM输出独立性假设的问题,还解决了MEMM的标注偏置问题,MEMM容易陷入局部最优是因为只在局部做归一化,而CRF统计了全局概率,在做归一化时考虑了数据在全局的分布,而不是仅仅在局部归一化,这样就解决了MEMM中的标记偏置的问题。使得序列标注的解码变得最优解。
- HMM、MEMM属于有向图,所以考虑了x与y的影响,但没讲x当做整体考虑进去(这点问题应该只有HMM)。CRF属于无向图,没有这种依赖性,克服此问题。