本文目录
Seq2Seq模型
定义
Seq2Seq全称Sequence to Sequence模型,即序列到序列模型。它是将一个序列信号,通过编码和解码生成一个新的序列信号,Seq2Seq模型的架构如下所示:
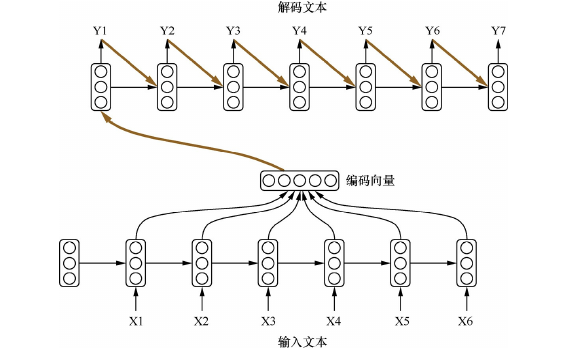
Seq2Seq在机器翻译、语音识别、自动对话、文本摘要等任务上有着很好的效果。在文本摘要任务中,模型的输入序列是长句子或段落,输出的序列是摘要短句。在图像描述文本生成任务中,输入是图像经过视觉网络的特征,输出的序列是图像的描述短句。进行语音识别时,输入的序列是音频信号,输出的序列是识别出的文本。不同场景中,编码器和解码器有不同的设计,但对应Seq2Seq的底层结构却如出一辙。
解码
Seq2Seq模型最核心的部分是其解码部分,大量的改进也是在解码环节衍生的。Seq2Seq模型最基础的解码方法是贪心法(greedy search),即选取一种度量标准后,每次都在当前状态下选择最佳的一个结果,直到结束。贪心法的计算代价低,适合作为基准结果与其他方法相比较。很显然,贪心法获得的是一个局部最优解,由于实际问题的复杂性,该方法往往并不能取得最好的效果。
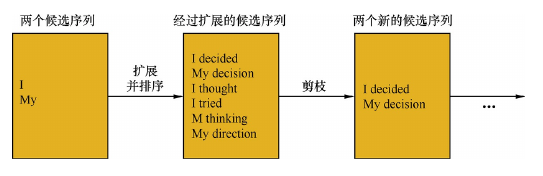
集束搜索是常见的改进算法,它是一种启发式算法。该方法会保存beam size(后面简写为b)个当前的较佳选择,然后解码时每一步根据保存的选择进行下一步扩展和排序(这句话的意思就是,解码时decoder中当前的状态应该是基于保存的选择做的运算。),接着选择前b个进行保存,循环迭代,直到结束时选择最佳的一个作为解码的结果。
下图是b为2是的集束搜索示例:
beam search在实际实现中比较复杂。之后会补充代码实现。